INTRO
Ontology engineering is how we take what experts mean and encode it so every system and service sees the world the same way.
Ontology engineering turns fuzzy human understanding of a domain into a clear structure machines can use.
Think of it as type systems and data modeling, but for meaning. If you’ve ever wrestled with messy business logic or schemas that don’t align, you already know why it matters.
First things first: What is an ontology?
In computer and information science, an ontology is a formal representation of the concepts in a domain, the relationships between them, and the constraints they obey. In Tom Gruber's classic definition, it is "an explicit specification of a conceptualization": you articulate your understanding of that portion of the world in a precise manner. Concretely, an ontology for a university might say:
- There are entities like
Plant,Tree,Shrub,Animal, andSoil. TreeandShrubare types ofPlant.- Animals can have a relation like
eats(Animal, Plant). - Trees can have a relation
growsIn(Tree, SoilType). - And a rule might say every
Treemust grow in some type of soil.
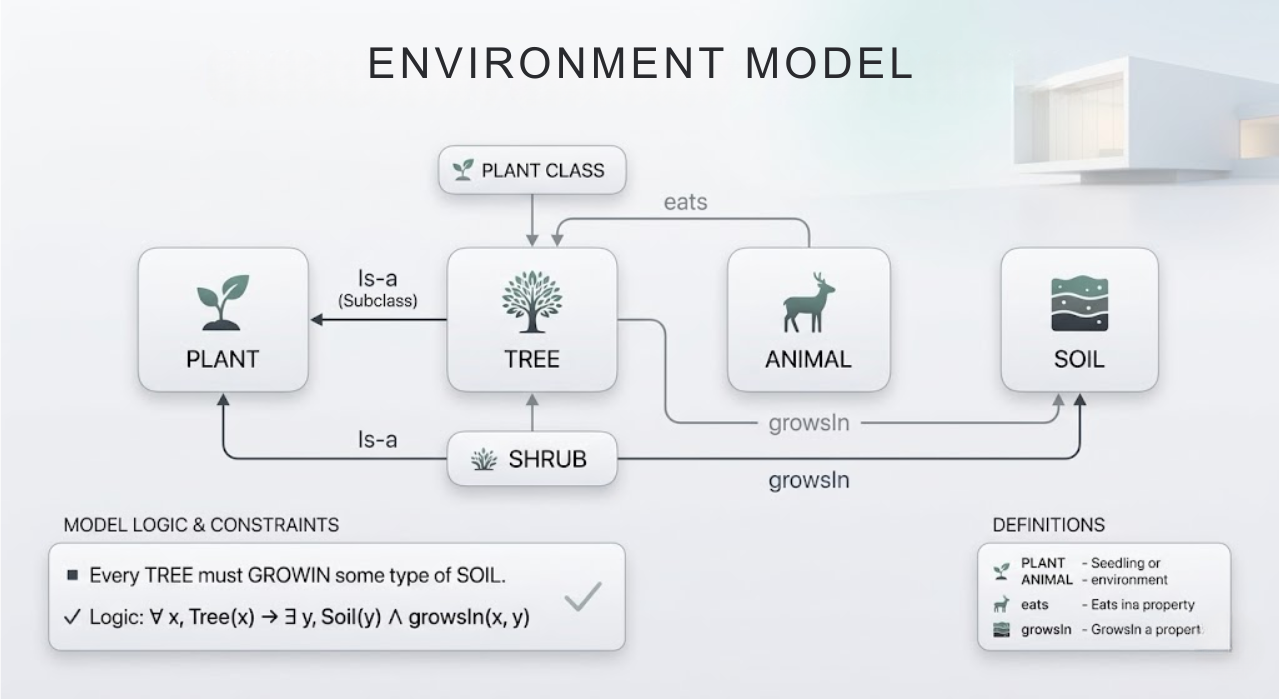
You can think of it as: ER diagram + strict terminology + logic. It's more complete than a schema, which is mostly about how to store things, because it includes rules and meanings that a reasoner can use.
What is ontology engineering?
If ontology is the model, ontology engineering is how we build that model systematically. In a formal sense, ontology engineering is the study of the ways, tools, and life cycle for creating ontologies. This includes choosing which concepts exist in a domain, what to name them, how they relate to each other, and how to encode them in a formal language.
To build a web of data, let's start with simple definitions:
That’s what the Semantic Web stack was designed to provide.
- RDF is a simple way to represent data as triples: subject → relationship → object. For example:
alice enrolledIn CS50. - OWL lets us define structure and rules. We can describe things like classes, relationships, and hierarchies.
- SPARQL is the query language for this data, similar to how SQL queries relational databases.
An ontology is the shared language that lets systems understand each other’s data. When two systems use the same ontology, software can often combine their data automatically, reducing or eliminating manual mapping.
In practice, ontology engineers
Sit down with domain experts and agree on precise meanings.
- What exactly is a customer?
- What counts as an order?
Model those ideas as classes, relationships, and rules.
Encode the model using standards like RDF and OWL so machines can store it, query it, and reason over it. Maintain it over time.
As systems and definitions evolve, the ontology evolves with them, preventing semantic drift. Ontology engineers are not just modeling data. They are architects of meaning, shaping how systems understand the world
Why the web needed ontologies
Web pages were mostly text and links. Humans could read them easily, but computers could not understand what the information actually meant.
So if one site says “CS50” and another says “Introduction to Computer Science”, a machine cannot tell they refer to the same course.
In a way, ontologies are the system design of a knowledge graph.
Fast forward to today and knowledge graphs show up in nearly every architecture diagram.
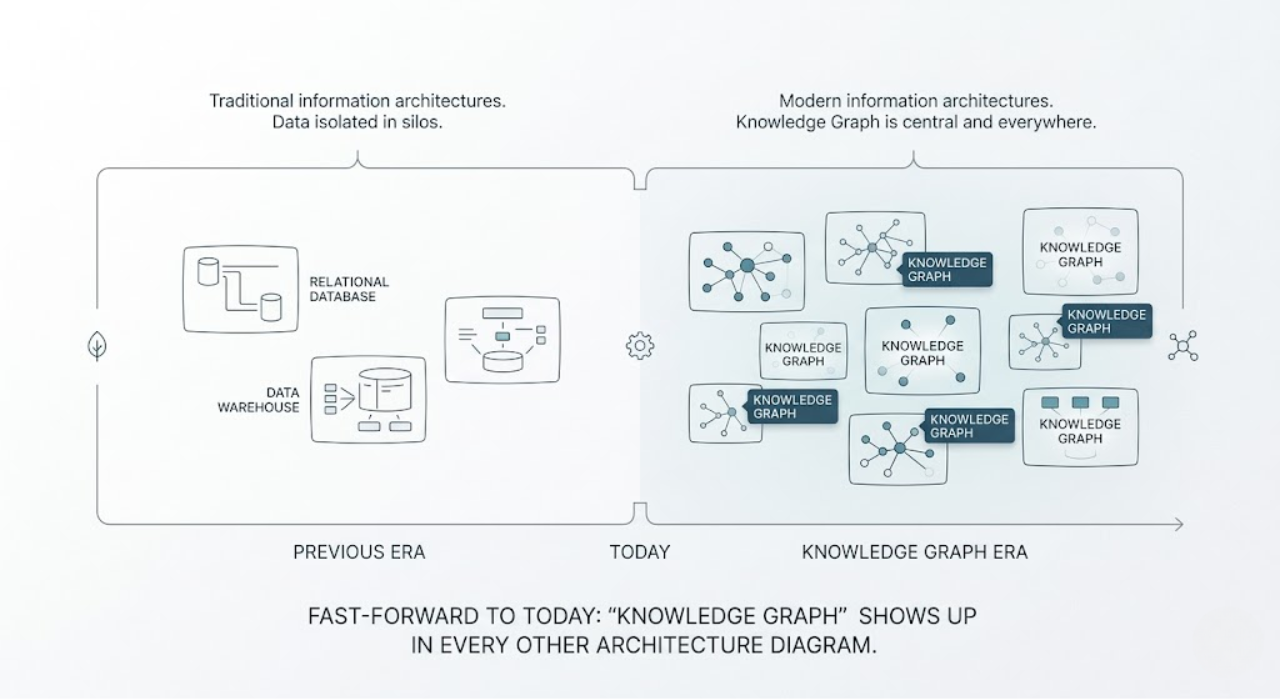
But look under the hood of any serious implementation and you’ll find something critical:
An ontology
It acts as the schema + semantics layer, defining the concepts, relationships, and meaning that make the graph usable, not just connected.
The ontology defines three things:
1️⃣ Entity types → what exists in the graph
Person, Book, Company, Diagnosis
2️⃣ Relationships → how entities connect
- worksFor(Person, Company)
- wrote(Person, Book)
- treatedWith(Diagnosis, Drug)
3️⃣ Constraints → what must always be true
- A Book has at least one Author
- A Person can work for many Company instances
- A Diagnosis must be linked to a Patient
Without an ontology, a knowledge graph is just a pile of nodes and edges. With one, it becomes a consistent, queryable model of the domain. This enables inference. If the ontology defines Tiger as a type of Animal, the system automatically knows every Tiger is also an Animal.
Why should we care
One of the primary methods for incorporating structure, meaning, and guarantees into your stack is through the use of ontologies, particularly when working with AI systems that extend beyond toy datasets.
1. Semantic search and QA
Ontologies help systems understand when different terms refer to the same medical concept.
For example:
- “Blood pressure test” and “BP measurement” can be recognized as the same procedure.
- A
Patientcan be linked to aDoctor, aMedication, and scheduledAppointments.
Because entities and relationships are explicit, systems can search the meaning of the data, not just the text.
Questions like “Which patients have appointments with cardiologists next week?” become simple graph queries instead of fuzzy text searches.
2. Data integration across systems
In practice, data engineering often means reconciling different names for the same thing.
One system says client_id.
Another says customer_id.
A third separates person and account.
Ontology engineering solves this by defining a shared model of the domain: what a Customer is and how it relates to orders, accounts, and contracts.
Each system maps its schema to that model.
Once that mapping exists, data can be integrated at the meaning level, not just by stitching columns together with joins and regexes. This also enables semantic interoperability. Different teams and vendors can exchange data while using the same definitions.
3. Reasoning and decision support
Ontologies also allow systems to reason over data.
For example, a system can:
- Infer new facts from existing data (e.g., derive a patient’s risk category from known attributes).
- Detect inconsistencies (e.g., someone marked as both
PediatricPatientandAdultPatient). - Enforce rules (e.g., flag treatments that don’t match the diagnosis).
This is why knowledge graphs with ontologies are often used in decision-support systems in healthcare, finance, and research. They don’t just give answers, they can also explain why a recommendation was made.
4. Grounding large language models
LLMs are great with text, but they don’t know your organization’s definitions, rules, or structure. They can misinterpret terms or invent fields.
An ontology-backed knowledge graph helps anchor the model in real data.
This lets you:
- Ground answers in verified entities and relationships from your graph.
- Disambiguate context (which “Jaguar” do we mean?) using defined concepts.
- Trace answers back to concrete data, making responses explainable.
The ontology is what gives the graph structure.
Without it, the graph is just data. With it, an LLM can use the data reliably and consistently.
Ontology engineering in practice
For engineers, ontology engineering will feel familiar. It’s very similar to the modeling work you already do, just at a slightly higher level of abstraction.
Instead of thinking in terms of tables and services, you start thinking in terms of meaning, relationships, and rules.
Here’s what the process usually looks like in practice.
1. Define the goal and questions
Start with the purpose. What problems are we solving, and what questions should the ontology answer? These competency questions define what the model must support.
2. Gather domain concepts with experts
Work with domain experts to list the key entities and relationships. Align on naming early to avoid confusion later.
3. Sketch a conceptual model
Model the domain as classes, relationships, and constraints. Think ER diagrams, but focused on meaning rather than tables.
4. Formalize in RDF or OWL
Translate the model into RDF or OWL using tools like Protégé. Define classes, properties, and rules, then connect the ontology to real data.
5. Test with competency questions
Turn the original questions into SPARQL queries. Use reasoners to validate logic and confirm expected inferences.
6. Iterate and maintain
Domains evolve, so ontologies must too. Version them carefully and update them as new concepts or rules appear.
How to lean into this
Start small. Build a tiny knowledge graph for a specific problem and back it with a simple ontology.
Focus on three things:
- Learn just enough ontology to model a small domain and query it.
- Treat your job not only as writing code, but shaping the meaning of data.
- Aim for shared definitions that machines can rely on across systems.
As systems become more connected and AI-driven, the real difference won’t be who has data.
It will be who has a shared understanding of that data.