If you’ve been following the Tabular – Databricks news, you’ve probably heard the phrase “metadata over compute.” It sounds like marketing, but it’s a real architectural idea. We use dlt (data load tool) to ingest into Apache Iceberg and watch how table metadata evolves and why it stays independent of the catalog.
The Thesis
Most data platforms tie table metadata to the compute engine. Your schema, partition info, and history live inside Snowflake, BigQuery, or Databricks. Move tables, and you leave that metadata behind.
Apache Iceberg inverts that. The source of truth is the metadata itself: JSON and Avro files that sit next to your data. The catalog (Hive, Glue, Snowflake Polaris, Tabular) is just a pointer: “this table’s metadata lives here.”
The metadata is portable. You can swap catalogs without losing history or lineage.
That’s “metadata over compute” in practice.
Operation → Metadata, in Succession
We use dlt’s filesystem destination with `table_format="iceberg"`. Same pipeline, three runs.
1. Append 5 rows
@dlt.resource(table_format="iceberg", table_name="events")
def events_append():
yield [{"id": 1, "event": "deploy", "ts": "..."}, ...]
pipeline.run(events_append())Metadata responds:
metadata/ has 2 file(s):
00000-....metadata.json
00001-....metadata.json
current-snapshot-id: 8570791162370934054
snapshots (history): 1
[1] append: parent=None added=5 deleted=0 total_records=5Each commit creates a new metadata file. Iceberg keeps the old ones.
2. Overwrite 2 rows (id 1 and 2 get new values)
@dlt.resource(table_format="iceberg", table_name="events",
write_disposition="merge", primary_key="id")
def events_overwrite():
yield [{"id": 1, "event": "deploy-v2", ...}, {"id": 2, "event": "build-v2", ...}, ...]
pipeline.run(events_overwrite())Metadata responds:
snapshots (history): 3
[1] append: added=5 deleted=0 total_records=5
[2] delete: added=0 deleted=5 total_records=0
[3] append: added=5 deleted=0 total_records=5Merge is modeled as delete + append. The chain is explicit.
3. Delete 1 row (id == 3)
@dlt.resource(table_format="iceberg", table_name="events", write_disposition="replace")
def events_after_delete():
yield [{"id": 1, ...}, {"id": 2, ...}, {"id": 4, ...}, {"id": 5, ...}]
pipeline.run(events_after_delete())Metadata responds:
snapshots (history): 4
...
[4] overwrite: added=4 deleted=5 total_records=4Replace drops the old data and writes only what remains. Final state: 4 rows. The full chain stays in the metadata.
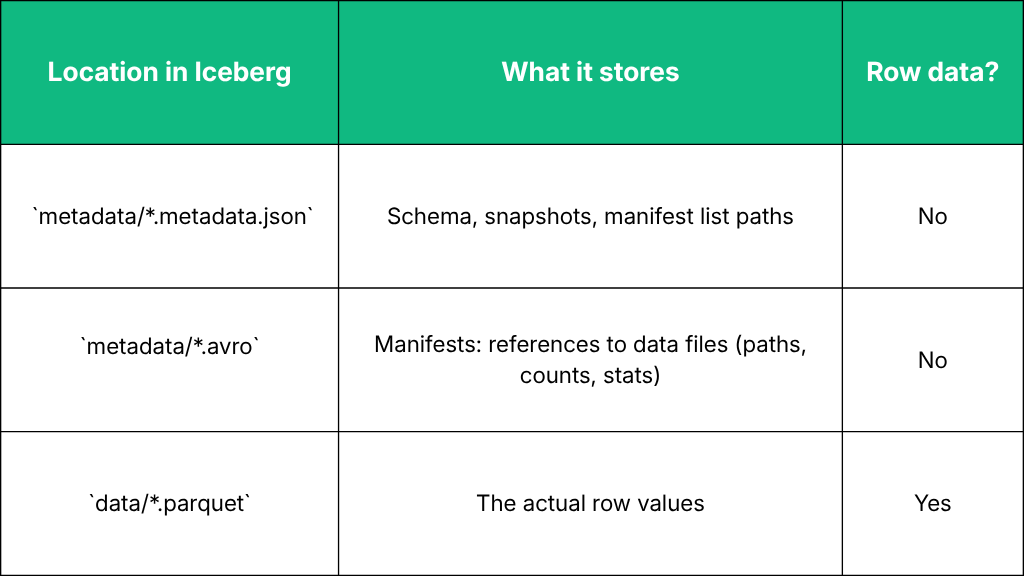
Where Does the Data Live?
The metadata points to the Parquet files. It doesn’t store the column values themselves.
Why This Matters
1.Portability - Metadata is just files. You can move them to another catalog (Polaris, Tabular) and keep the same history and lineage.
2. Auditability - `snapshot-log` and `metadata-log` give a clear record of what changed and when.
3. Time travel - Snapshots form a chain via `parent`. You can query the table as it looked at any past snapshot.
4. Catalog independence - The catalog is only a mapping from table name to metadata location. The same metadata files work with Hive, Glue, Polaris, or Tabular.